

An artist/designer is involved at all stages of the process.
The process begins with an existing image—typically a photograph—which is then manipulated via software.
All of the computer-generated art that I do is pure algorithmic art, i.e., depends solely on algorithms (see below), with no inputs other than random numbers. My algorithms do not operate on existing images, and once an algorithm has been designed and implemented in code (software), the human is "out of the loop" (except of course that someone must judge the final product).
Each algorithm can be thought of as a mathematical function that converts a pair of numbers—x- and y-coordinates that identify a location on the computer screen or on a piece of paper—into a single number or triple of numbers that in turn specifies a color (see below). Interesting algorithms can be obtained by combining trigonometric functions (e.g., sine and cosine), polynomials, and other standard functions, but one may also use more specialized functions as building blocks. These building blocks are combined using sums (addition and subtraction), products (multiplication), ratios (division), and compositions (the output of one function becomes the input to another function).
The final algorithm almost always produces "real" (floating point) numbers; these numbers are converted into colors via one of two basic methods:
When one uses a palette, one can think of the algorithm/function and the palette as essentially independent, i.e., one can change one without changing the other. The two Whirlpool images below use essentially the same function (the parameters are slightly different), but appear at first glance unalike because of the different palettes.
Certain applications require small palettes. For example, some of my designs have been adapted for use in knitted clothing created by computer-driven machines. The limits of these machines constrain one to use a palette containing no more than four colors. Many printing processes place limits on both the number of colors and on the range of allowed colors.
There are unlimited possibilities for variations on the above basic ideas. One variation that has yielded good results for me is to sum several similar but non-identical functions, translating these different versions (i.e., shifting them spatially) before adding them together. This technique was used in the African masks images below. Another variation is to select function/algorithm parameters using pseudorandom numbers. The three versions of red and green plants were all generated using the same algorithm; different values of the function parameters produced the three rather different outputs.
The CPU time required to generate an image is typically proportional to the number of pixels in the image, with the constant of proportionality depending on the specifics of the algorithm. If the image fills a typical computer screen with roughly 1 million pixels, the algorithm complexity must be constrained by the need to generate the image in a reasonable amount of time. Greater algorithmic complexity can be handled by dividing the calculations over multiple cores within a single computer, by using the graphics processing units (GPUs) within the graphics cards to execute the algorithm (rather than only for displaying the results), by dividing calculations over a cluster of computers, or by a combination of these techniques.
I started experimenting with computer art in 1976. At that time, the tools were incredibly primitive. The best graphical output was generated using a pen plotter. Today's generation has never seen one of these devices. It could take up to an hour to produce one page of output, at which point one might realize that the algorithm needed fixing. What was impossible in 1976 is relatively easy with today's technology. If the algorithm complexity is modest, one can tweak the algorithm and see the result in a matter of seconds.
There are still many challenging problems waiting to be solved. For example,
when function parameters are generated using pseudorandom numbers, only a small
percentage of the images generated by the algorithm are likely to be
interesting. Currently, a human must sort the output to decide which images are
worth keeping. What makes some of these images interesting while others are not?
Can we develop software that is smart enough to be trained to identify the
interesting images automatically? Who knows what the next 37 years of
technological change will bring?
 |
 |
 |
| 1. Immiscible Liquids | 2. Nested Boxes | 3. Islands |
 |
 |
 |
| 4. Unnamed | 5. Unnamed | 6. Starry Night |
 |
 |
 |
| 7. African Masks #1 | 8. African Masks #2 | 9. Unnamed |
 |
 |
 |
| 10. Red and Green Plants Coexisting | 11. Red and Green Plants Competing for Space | 12. Red and Green Plants at War |
 |
 |
|
| 13. Butterflies #1 | 14. Butterflies #2 | 15. This Space for Rent (just kidding) |
 |
 |
 |
| 16. In the Womb—Not Yet Growing | 17. In the Womb—Developing | 18. In the Womb—Ready to Emerge |
 |
 |
 |
| 19. Gravity Waves #1 | 20. Gravity Waves #2 Caution: Don't stare for too long! |
21. The Sun is a Peacock |
 |
 |
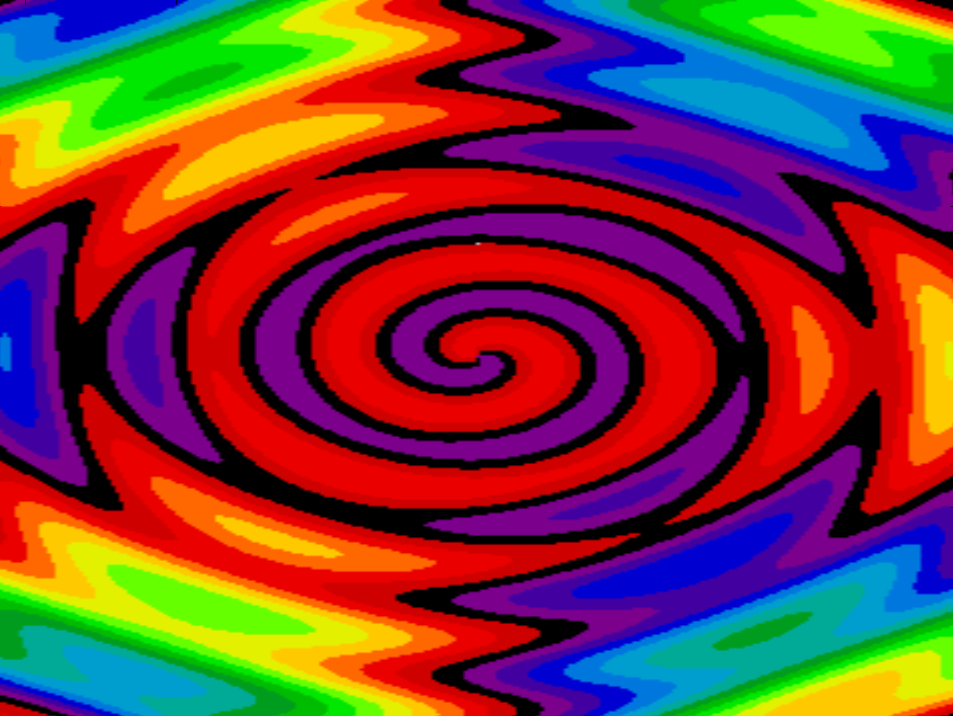 |
| 22. The Four Elements | 23. Whirlpool 1 (Pickover's Function) |
24. Whirlpool 2 (Pickover's Function) |
 |
 |
 |
| 25. Burning Sand | 26. He Separated the Waters Above from the Waters Below |
27. Stretched But Not Yet Broken |
 |
 |
 |
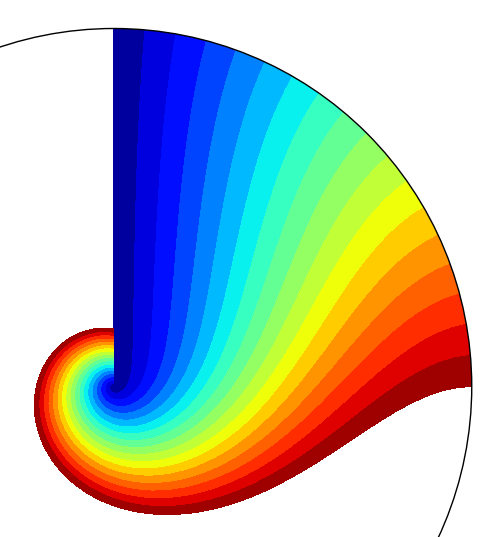
| 28. Hidden Wellspring #1 | 29. Hidden Wellspring #2 | 30. Bird Sunning Itself |
 |
||
| 31. Gem Guarded by a Spider |
In The Four Elements, I cheated by modifying the palette after the fact. In the original, one of the four colors was purple. I replaced it by brown to create a better balance of hues and make the color scheme fit the title. Click here to see the original and modified images side by side.
6, Feb, 2016: After allowing this gallery to lie fallow for almost three years (since March of 2013), I added three new images— numbers 28—30:
Number 28 was the result of a complete accident. I was generating a polar plot (type of visualization) for purposes of understanding a mathematical transformation from one system of coordinates to another. A mistake in the code produced this intriguing pattern.
Number 29 was the result of a calculated manipulation of the code that produced number 28; the theta angle (angle from the x-axis) must traverse more than 360 degrees to produce a pattern without a gap.
It is generally thought that pure algorithmic art is representational rarely and only by accident. I created image number 30 to demonstrate that this is not necessarily the case, and that recognizable motifs can be obtained by design in pure algorithmic art. No drawing of any kind was employed in the creation of this image. (Considerable tinkering with the function and the color palette was, however, required). Because image 30 bears little resemblance to images 28 and 29, the reader may be surprised to learn that all three images were produced by variants of the same function. (The function that produced image 30 has two additional terms—one for the eye-spot and another for the sunrays.
Free non-commercial use of these images is permitted as long as the source is acknowledged.